Counting assembly instructions
As someone who may or may not procrastinate, I find myself shaving yaks occasionally. One such yak shave occurred recently while working on a project for my operating systems class. We were provided with an assembly file written in x86 GNU assembly syntax. I wondered if the file contained any instructions I wasn’t familiar with or hadn’t used in awhile. My first task was to figure out all of these unique assembly instructions, look them up in the Intel manual, and use them (plus 1-2 others) for the code I was going to write.
The assembly file itself was ~200 lines of code, so it was not unthinkable to count them by hand, determine what the unknown instructions were, and look those up.
Just kidding! I needed to be efficient and decisive. Since I perform this task yearly (?), I also judged if it was worth the time to make this task more efficient. My calculations were influenced by procrastination, so naturally the answer was “yes - I must write a bash script to do this”.
First try
My first attempt at a shell script looked like this:
#!/bin/bash
# count_mnemonics.sh
#
# This script counts the number of unique assembly mnemonics
# in an assembly file. Assumes a tab character before every
# assembly instruction
asfile=$1
if [[ -z $asfile ]]; then
echo "Error: please provide an assembly file" 2>&1
exit 1
fi
touch tmp
IFS=''
while read -r line; do
if [[ $line == *$'\t'[[:alpha:]]* ]]; then
line=${line#*$'\t'}
echo "${line%% *}" >> tmp
fi
done < "$asfile"
sort tmp | uniq -c | sort -rn
rm tmp
The provided assembly file had a tab character in front of each mnemonic, which
reduced the job of finding instructions to finding 0x09 bytes. Some
positives:
- I finally used
readproperly. I’ve always followed the pattern ofbutcat "$file" | while read line; do # perform line operations doneshellcheckinformed me thatcatwas unnecessary. I’d run into this a few times before, but I could never find themanpage for thereadcommand in my bash shell (not even usingman 1p!). Little did I know that bash doesn’t have man pages for builtin commands… andreadis a builtin command for bash. Anyway, I found the example that I needed, and redirected the assembly file at the bottom of the while loop. 1 - The
sort/uniqpattern. I haven’t used this in a script before for whatever reason, but listening to Matt Godbolt and Ben Rady talk about the pattern on their podcast made this an easy one-line addition to the script.
The script got the job done and produced output that looked like this:
30 movw
11 int
6 movb
6 inb
6 call
5 pushw
5 popw
5 outb
5 incw
4 loop
4 incb
4 decw
4 addb
3 xorb
3 jmp
2 jge
2 cmpb
1 xorw
1 shrb
1 ret
1 andb
My script works. My task is complete. Or is it?
Though it may pass shellcheck, there are some things one could improve upon in
this simple script. Some of the more glaring ones that I noticed were:
- Creating the file
tmp. I wrote and ran this script in a relatively clean directory that I controlled. If I want to make this more portable, I need to consider the possibility thattmpexists in the same directory as whatever the script is being run in. What if I’m running in the root directory (where/tmpexists)? My script doesn’t even check if this file exists! What if appending to a file with data?! - There are tools for string parsing. Several that come to mind are
cut,sed,awk, andperl. You can do an incredible amount of text manipulation and string parsing withbash, but if you’re not careful it is quite easy to shoot yourself in the foot. 2
Replacing tmp with |
If we want to follow The Unix Way™ in avoiding the creation of tmp, one tool
we might consider using is the humble pipe. The second tenet of the Unix
philosophy
(as documented by Doug McIlroy) is:
- Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don’t insist on interactive input.
A pipe is a form of inter process communication (IPC) that is as old as Unix itself. Data flows in one direction, uniting the standard output of one command to the standard input of the next. 3 Pipes are the load-bearing feature of a Unix-based OS that implements this aspect of the philosophy. We can avoid “clutter[ing] output with extraneous information” by not adding another named file to the filesystem that might interfere with our operation.
In the first iteration, pipes are used to unite the last set of sort/uniq
commands, but they don’t connect them with the string parsing. We can reorder
our commands to redirect output from the while loop into our output sequence.
IFS=''
while read -r line; do
if [[ $line == *$'\t'[[:alpha:]]* ]]; then
line=${line#*$'\t'}
echo "${line%% *}"
fi
done < "$asfile" | sort | uniq -c | sort -rn
cut and awk and sed and perl
Currently, we use bash builtins such as the test command ([[ ]]) and string
replacement (${variable##substr}) when parsing each line of the assembly file,
as well as a full while loop with the read command. What if there was a
different way? 4
cut
The cut command allows one to extract text from input lines based on different
arguments that we specify. We can choose to extract (f)ields, (b)ytes, or
(c)haracters - either a single instance, or a range (or ranges). cut is
extremely effective when working with well-structured files, such as .csv
(comma-separated values) files, lists of path names, or tab-separated data.
In our case, we want to select lines that have the pattern of a tab character followed by a mnemonic, followed by a space. These may be of different lengths, so the command will use fields. To do this with cut, we can use the command
cut -f 2 asfile.s -s | cut -f 1 -d ' ' -s | grep -v '\..*'
The first cut outputs the first field after a tab character (the default
delimiter), removing all lines that don’t contain a tab. The second cut
outputs the first field before the space character, which removes all assembly
operands after a mnemonic.
Sadly, we need to add a grep command as well. cut doesn’t support the
removal of lines with a specific delimiter character, only the removal of lines
without one. We want to get rid of lines beginning with ., as these are
assembly directives. Alas, our necessary grep.
awk
AWK is a beast of a language that is
engineered for text processing and data extraction. It is named after its
authors (and legends in the field) Alfred Aho, Peter Weinberger, and
Brian Kernighan. Far from being a dead has-been shell utility, awk is
still
maintained
and the one true awk is still being contributed
to
by bwk. Most users use gawk, GNU’s awk implemented by the FSF in 1988, as it
is the default on Linux systems (it uses the GPL license). Sadly, the author
is no different, and has not committed to adding the one true
awk with Unicode
support
to his system path.
The following gawk command will do the trick for our assembly file:
awk -F'\t' '{split($2, a, " "); if (a[1] !~ /^\./ && length(a[1]) > 0) print a[1]}'
We set our delimiter to the tab character and extract the second field of each
separation along \t into an array, with each array element split by ' '. We
then examine the first element of the array: if it’s not a blank line or an
assembly directive (beginning with '.'), we output the value. To use on
asfile.s, we append the filename to the end of the command.
This command is a bit complex, and took some conversations with Claude to sort
out. You’ll notice at first glance that it’s more involved than our cut
command. A disadvantage when first using awk is that it is a full language:
you have to understand its syntax, rules and other quirks in order to use (or
even know about) all of its features. cut is a much narrow Unix utility, and
is simpler to use for this task, but it cannot perform many of the operations
awk is capable of. Additionally, this is one command; our cut sequence was
three separate commands (and one of them was grep!).
sed
In the beginning, there was
ed. Arguably, in the lineage we
are concerned about, qed
came first (1965 vs. 1969), but who’s counting? Scripting features of both
original text editors led Lee McMahon to create the stream editor,
sed. It is the successor to
the grep command, which also was born
out of ed (for those who may not know, g/re/p originally stood for a
global regular expression that prints matching lines in ed).
sed functions as a line-oriented editor that, instead of printing matching
regular expressions, substitutes different strings in place (as the man page
says, “perform[s] basic text transformations on an input stream”). Again, we
will use the GNU version of the sed utility (as opposed to the BSD
implementation). The line that works for our purposes is:
sed -nE '/\t[[:alpha:]]/s/.*\t([[:alpha:]][^ ]*).*/\1/p' asfile.s
sed regular expressions are patterned on the (now standard) 5
cmd/pattern/substitution/cmd
where cmd is a one-letter command directive, such as substitute (at the
beginning) or global (at the end). In our case, the first command is an
address pattern. It matches lines that contain a tab followed by an alphabetic
character (our mnemonics), avoiding directives, lines without tabs, etc. It then
use the substitution command to pattern-match the substring from the \t
character up to the first space character - ([[:alpha:]][^ ]*) selects every
non-space following the first alphabetic character. The first argument of that
pattern-match is selected and printed, and can be piped into our
sort/uniq utility pipeline.
The regular expression here is more complicated than that in awk, but slightly
shorter (less than 80 characters). Here, we add the flags -n to print only
matching lines and -E to use extended regular expressions (so that we don’t
have to escape the ( ) characters).
perl
As the great Steve Yegge once said, 6
Perl. It’s a swiss army knife. You can use it to sidestep this problem with honor, by disemboweling yourself.
perl -lne 'print $1 if /\t([a-z]\S*)/' asfile.s
How far did we get?
Well, we’ve reduced our 27-line script to a one-liner
perl -lne 'print $1 if /\t([a-z]\S*)/' asm.s | sort | uniq -c | sort -rn
which fits under 80 characters, and is still fairly readable.
But now that we’ve reduced our file size, we have so many more features to add:
- We could add more information to this output. We could include statistics based on information that we’ve ignored so far. GNU assembler syntax specifies operand size as a suffix to the instruction. What word sizes are involved? We also remove the operands when parsing. How many operands are immediate vs. register-to-register vs. memory?
- Currently, this script ignores assembly directives. What if we wanted to print those separately?
- How many cycles does each instruction take, on average? What about
sub-averages by file section? How many are data movement instructions (
movw) versus arithmetic-logic unit (ALU) instructions (incb) versus control flow instructions (jge)? 7
We can also think about generalizations:
- This only works for GAS-formatted syntax produced by
gcc -Sor someone who prefers tabs over spaces in their default editor. How do you account for spaces before a mnemonic? - How could this generalize to parse other assembly files, for instance, x86 or RISC-V or ARM ISAs? How could you calculate the desired statistics on those?
To answer a few of these feature requests, I modified my shell script as follows:
#!/bin/bash
# countasm.sh
#
# This script provides basic information about an assembly file written in GNU
# assembler syntax.
asm=$1
if [[ -z $asm ]]; then
echo "Error: please provide an assembly file" 2>&1
exit 1
fi
echo -e "Information about $asm"
echo -e "\nTop 10 assembly instructions"
perl -lne 'print $1 if /\t([a-z]\S*)/' "$asm" | sort | uniq -c | sort -rn | head
echo -e "\nOperand sizes (b: 8, w: 16, l: 32, q: 64)"
perl -lne 'print substr($1, -1) if /\t([a-z]\S*[bwlq])\b/ && $1 ne "call"' \
"$asm" | sort | uniq -c | sort -rn
echo -e "\nAssembly directives"
perl -lne 'print $1 if /\t([.]\S*)/' "$asm" | sort | uniq -c | sort -rn
echo -e "\nRoutine names"
awk -F":" 'NF>1 && !/^#/ { print $1 }' "$asm" | sort | uniq | sort -rn | column
The new output of this script is
$ ./countasm.sh vga16.s
Information about vga16.s
Top 10 assembly instructions
30 movw
11 int
6 movb
6 inb
6 call
5 pushw
5 popw
5 outb
5 incw
4 loop
Operand sizes (b: 8, w: 16, l: 32, q: 64)
50 w
32 b
Assembly directives
2 .byte
1 .org
1 .globl
1 .code16
Routine names
2 1 print _start
Granted, I’ve used the same hammer to hit three different nails at this point (and should probably write a separate function or perl script), but not bad. There’s a bit more functionality packed into that short script.
To expand further, I’d next focus on getting data on operands, then classifying
instructions as data/ALU/conditional, adding more categories as I went. I’d also
start to define functions and potentially decide on a language to best handle
string substitutions. Maybe perl.
Professional tools
One thing that you might notice is I’m trying to parse a text file (specifically, an assembly file). One logical step past scripting would be to write a real parser, a core feature of compilers.
Parsers are very useful. You can define grammars and create abstract syntax trees, which provide a representation of the program or text you are trying to understand. If I wanted to delve further into the structure of the assembly file and try to understand memory vs. CPU-heavy sections, or preemptively identify hot loops and unoptimized code, this could be the way to go.
Another useful tool operates in the opposite direction. When trying to derive
meaning from machine code, people look to
disassemblers to translate from
machine language into assembly code. The countasm tool could help once code is
translated back into assembly to more quickly identify common patterns and
add tags and labels to the code (in a world where countasm provides a much
deeper analysis than it did today).
Static analyzers do what I attempted to do here and much more. A while back,
John Carmack wrote about just how important static analysis
is to writing good code. GCC has
the -fanalyzer
flag
that goes to serious lengths to identify issues with code at compile
time. Imagine writing a buffer overflow in your C program and getting this
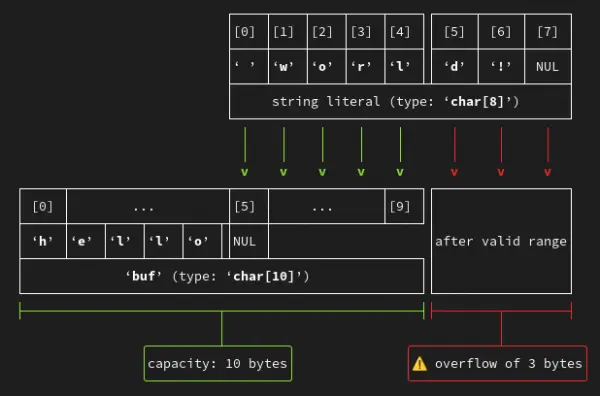
helpful diagram:
Beyond bash
Shell scripts can only take you so
far
before the overhead becomes too much to handle: you spawn many processes, you
use tools that aren’t quite right for your purposes, you learn how powerful rm -rf really
is,
you delete six servers in one
move, you add your
name to the list of Unix horror
stories…
At the end of the day, you’re better off writing your utility in a maintainable
language that has OS-provided guardrails to help you, some form of type
checking, a debugger that is not set -x, and performant libraries. Real tools
are not written in bash.
However, if you are ever asked to find the phone numbers in 50,000 HTML pages, you know where to start. For every well-polished and maintained tool in the world, there is an ugly, unportable script holding some piece of critical infrastructure together. 8
Resources
Outside of manual pages, Charles Cabergs
has a great YouTube channel with high-quality videos on advanced C programming
and other topics. If you enjoyed the string parsing, look at his recent videos
on cut and
sed. I happened to find his
content as I was finishing this, and the videos were helpful beyond man sed
and the HTML pages.
-
A good place to look for more information is the Bash Hackers Wiki page on
read. ↩︎ -
Bash is often known for its gotchas, and string parsing is no exception. Though it has great builtin support, unless you are very aware of the behavior of what you’re using, you can quickly run into trouble. For example, my script no longer works if I change line 21 from shortest prefix matching
line=${line#*$'\t'}to longest prefix matching
line=${line##*$'\t'}(and that’s only on the single file I was working on). ↩︎
-
Note that there are different kinds of pipes: for example, stream pipes allow for data to flow in both directions (with two different file descriptors for reading and writing), and FIFOs and named pipes allow for IPC between processes that don’t have a common ancestor. In this script, data flows in only one direction and all processes have a common ancestor (our subshell that is created when executing this script), so it’s okay to stick with
|for now.I’d recommend this blog post for a quick note on the beauty of pipes, and reading Rob Pike and Brian Kernighan’s original paper for how pipes fit into general Unix program design. For how the Unix kernel implements pipes, look here. ↩︎
-
Or, in this case, several different ways. Even within each one-liner I’ve written, there are likely more efficient or more concise ways to extract the desired fields. Send me a note if you have suggested improvements - I’d love to know! ↩︎
-
There is no explicitly standard, but since the days of
ed, this pattern for regular expression matching has continued into many other scripting languages.awk,perl,bash,vim, Ruby, and even the operating systememacs(usingsed-mode) all feature this pattern. Today, it is more common for modern scripting languages such as JavaScript and Python to use method or function calls from a core language library on string objects, as opposed to parsing ASCII or text streams. ↩︎ -
See this incredible post on compilers for context. ↩︎
-
Many of these would require a bit more information outside of the assembly file ↩︎
-
Not the most appropriate reference: I’m sure the random person in Nebraska’s project is maintained quite a bit better than my
~/toolsdirectory. ↩︎